DexMachina: Functional Retargeting for
Bimanual Dexterous Manipulation
Annoymized Codebase
Abstract
We study the problem of functional retargeting: learning dexterous manipulation policies to track object states from human hand-object demonstrations. We focus on long-horizon, bimanual tasks with articulated objects, which is challenging due to large action space, spatiotemporal discontinuities, and embodiment gap between human and robot hands. We propose DexMachina, a novel curriculum-based algorithm: the key idea is to use virtual object controllers with decaying strength: an object is first driven automatically towards its target states, such that the policy can gradually learn to take over under motion and contact guidance. We release a simulation benchmark with a diverse set of tasks and dexterous hands, and show that DexMachina significantly outperforms baseline methods. Our algorithm and benchmark enable a functional comparison for hardware designs, and we present key findings informed by quantitative and qualitative results. With the recent surge in dexterous hand development, we hope this work will provide a useful platform for identifying desirable hardware capabilities and lower the barrier for contributing to future research.

Method
Method Overview
We propose DexMachina, a novel algorithm that achieves functional retargeting for a variety of hands and objects. At a high-level, we train an RL policy using a virtual object controller curriculum, guided by both a task reward and auxiliary rewards.
Task and Auxiliary Rewards
Given one demonstration, we first use its object states to define task reward. Next, we run a collision-aware kinematic retargeting procedure, which produces reference dexterous hand motions: we use them for motion imitation reward and residual wrist actions. We then approximate hand-object contact positions, which we use to define contact reward.
Virtual Object Controller Curriculum
The reward terms and residual action learning can sometimes achieve short and simple tasks, but struggle on long-horizon clips with complex contacts, where the policy often experiences catastrophic early failures. This motivates us to propose a novel curriculum approach, to let the policy explore different strategies in a less fragile setting.
Experiment Results
Experiment Setup
To evaluate dexmachina, we use a subset of ARCTIC data which includes 5 articulated objects and 7 clips consisting of diverse motion sequences and both long and short-horizon demonstrations. We curate assets for 6 open-source dexterous robot hand models, with varying sizes and kinematic designs.
DexMachina outperforms baseline methods across all tasks and hands
We first evaluate on 4 hands. We compare dexmachina with direct replay of kinematic retargeting results, two baseline methods, and training with our proposed rewards but without curriculum. With rare exceptions, our method consistently achieves the best performance across all the hands and tasks, especially on long-horizon tasks with complex motion sequences.
Kinematic retargeting does not produce feasible actions
Without policy learning, kinematic retargeting can produce human-like hand motions, but when we play the retargeting results in simulation, they are not feasible for completing the task.
DexMachina handles long task horizons without early failures
Compared to ObjDex baseline which uses only task reward, our method can handle longer horizon tasks without early failures.
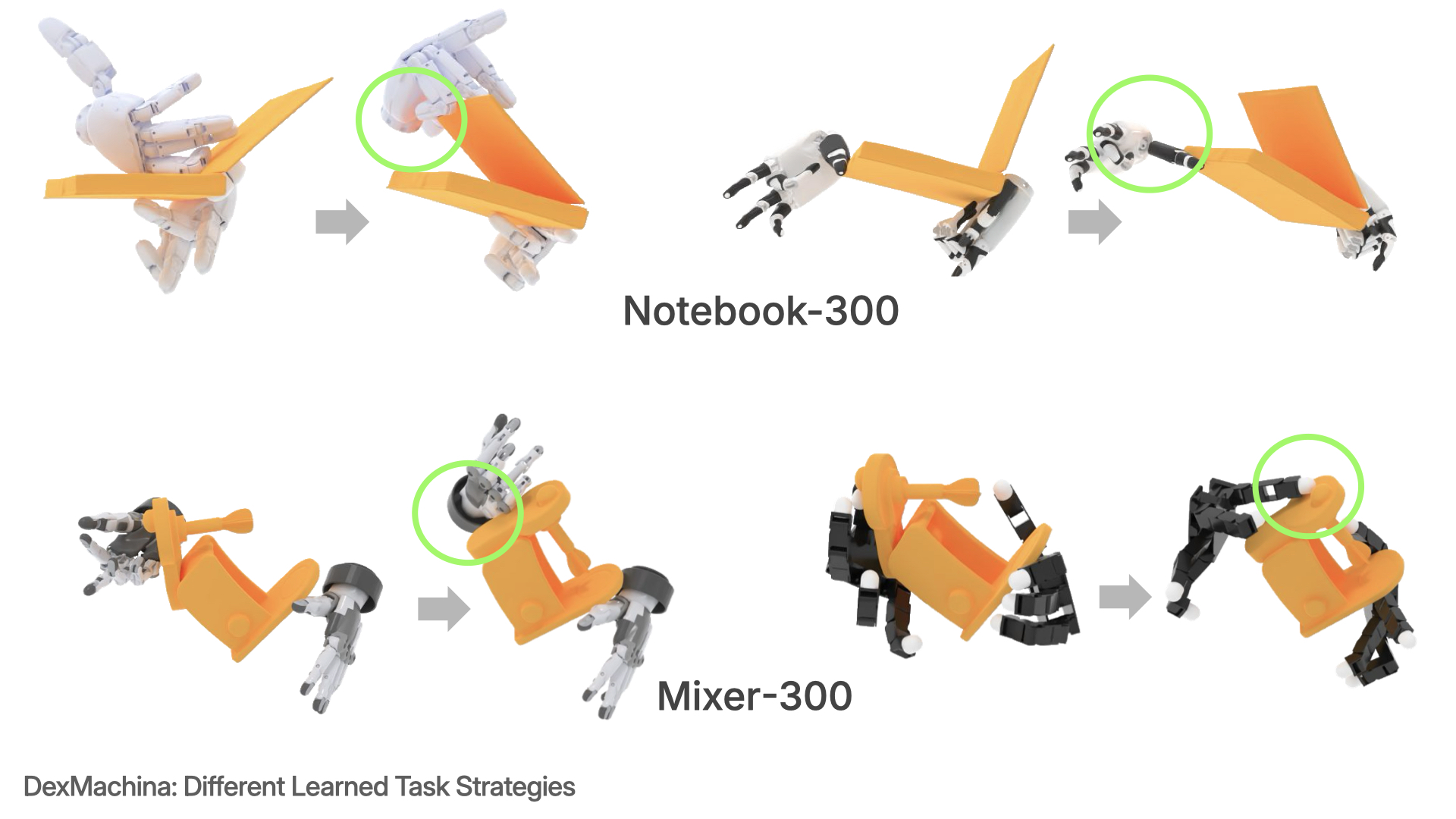
DexMachina allows policies to adapt to their hardware constraints
For example, on the Notebook task, the XHand policy follows the human demonstrator to use the left hand to hold up the object and the right hand to close the cover, But for the smaller, less-actuated Inspire Hand, the policy learns to use both hands to stabilize the object and close the cover, despite using the same human hand motion reference as Xhand. Similarly, for the Mixer task, Allegro Hand uses its longer and more flexible thumb to close the mixer lid, but Schunk Hand learns to move the wrist forward and close with its palm.
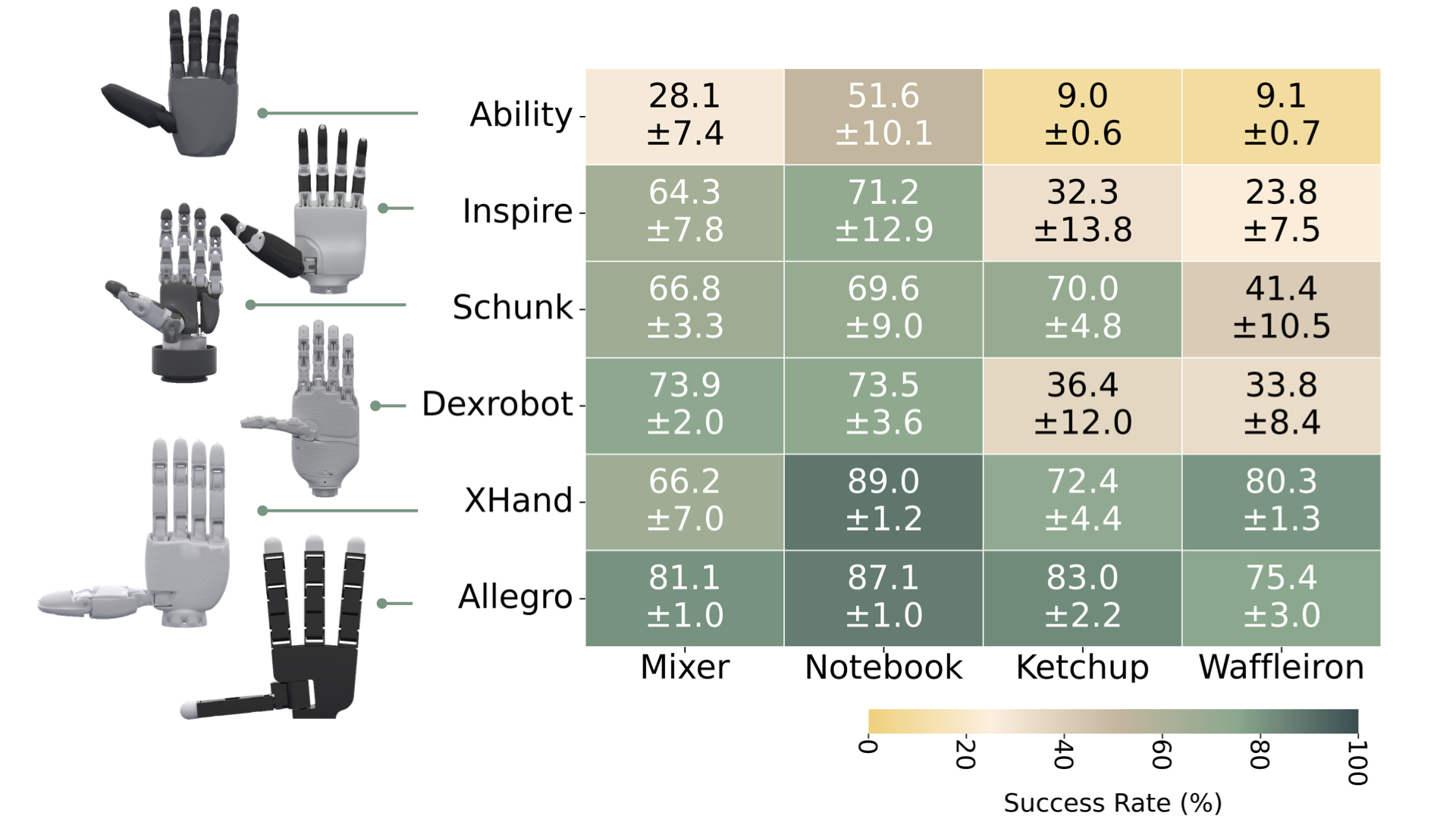
DexMachina enables a functional comparison between hardware designs
With an effective functional retargeting algorithm, we can now perform a functional comparison between different dexterous hands. We focus on the 4 long-horizon tasks, and evaluate dexMachina on two additional hands. We compare the performance of all the hands and discuss key empirical findings. Overall, we see the larger, fully-actuated hands can achieve both higher final performance and better learning efficiency. Interestingly, degrees of freedom is more important than hand sizes. Schunk hand and Xhand, for example, have more actuated fingers, and perform much better than Inspire hand and ability hand which are similar in size to human hands With the recent surge in dexterous hand development, we hope our work will provide a useful platform, that can help identify desirable hardware capabilities and lower the contribution barrier for future research.
Additional Policy Evaluation Videos
Using our method on the 3 short-horizon tasks, all hands can achieve between 70 to up to 90% success rate in object tracking AUC-ADD metric.
Feasibility of Arm Kinematics
We use a basic IK setup to qualitatively demonstrate the feasibility of extending DexMachina to consider robot arm kinematics. In the below videos, we use our trained RL policy to produce bimanual wrist poses for a pair of dexterous hands, then use the wrist poses as targets for inverse kinematics (IK) to generate arm joint values for a Fourier GR1 humanoid robot. Despite occasional jittering motions, we remark the learned wrist actions are generally achievable by robot arms, and a promising direction for future is extending our RL training to full arm control, or further constrain the wrist motion range to adapt to arm-specific kinematic constraints.
RL with Domain Randomization
To address the conern regarding robustness of learned finger motions, we provide additonal experiments where we randomize the physics parameters during RL training. Videos below show qualitative comparison between a policy trained without randomized physics, and another policy trained in the same setup but the object's mass is randomly varied (we add a delta mass value randomly sampled from -0.1kg to 0.5kg). We observe the policy trained with randomization (left video) learns to make more stable contact between the Inspire hand and ketchup bottle, while achieving similar object tracking accuracy as the original policy trained without randomization (right video). These results suggest incorporating domain randomization during training can improve the robustness of learned behavior, to make it less brittle to changing object dynamics, and potentially facilliate sim-to-real transfer, which is a promising direction for future work.
Reward Weights Ablation
We provide additional experiments to show the effect of different reward weights on policy performance. The maximum achievable reward for both the task reward and each auxiliary reward term is always 1.0, and the task reward is always weighted with 1.0. In the experiments below, we vary the weights for motion imitation, behavior cloning and contact rewards, while keeping other settings exactly the same. Each curve uses a different combination of reward weights, and we plot the task reward (which directly reflects object tracking performances) and auxiliary rewards. The sub-plot 'Episode Task Reward' plots the cumulative task reward achieved in each episode, which directly reflects the policy's object tracking performance. Although we could not finish an exhaustive pass on all the possible weight combinations due to the limited bandwidth during this rebuttal period, we remark the overall trend that the task performance is relatively robust to different auxiliary reward weights. The slight fluctuations in the Episode Task Reward curves will likely be smoothed out when averaged across multiple random seeds.
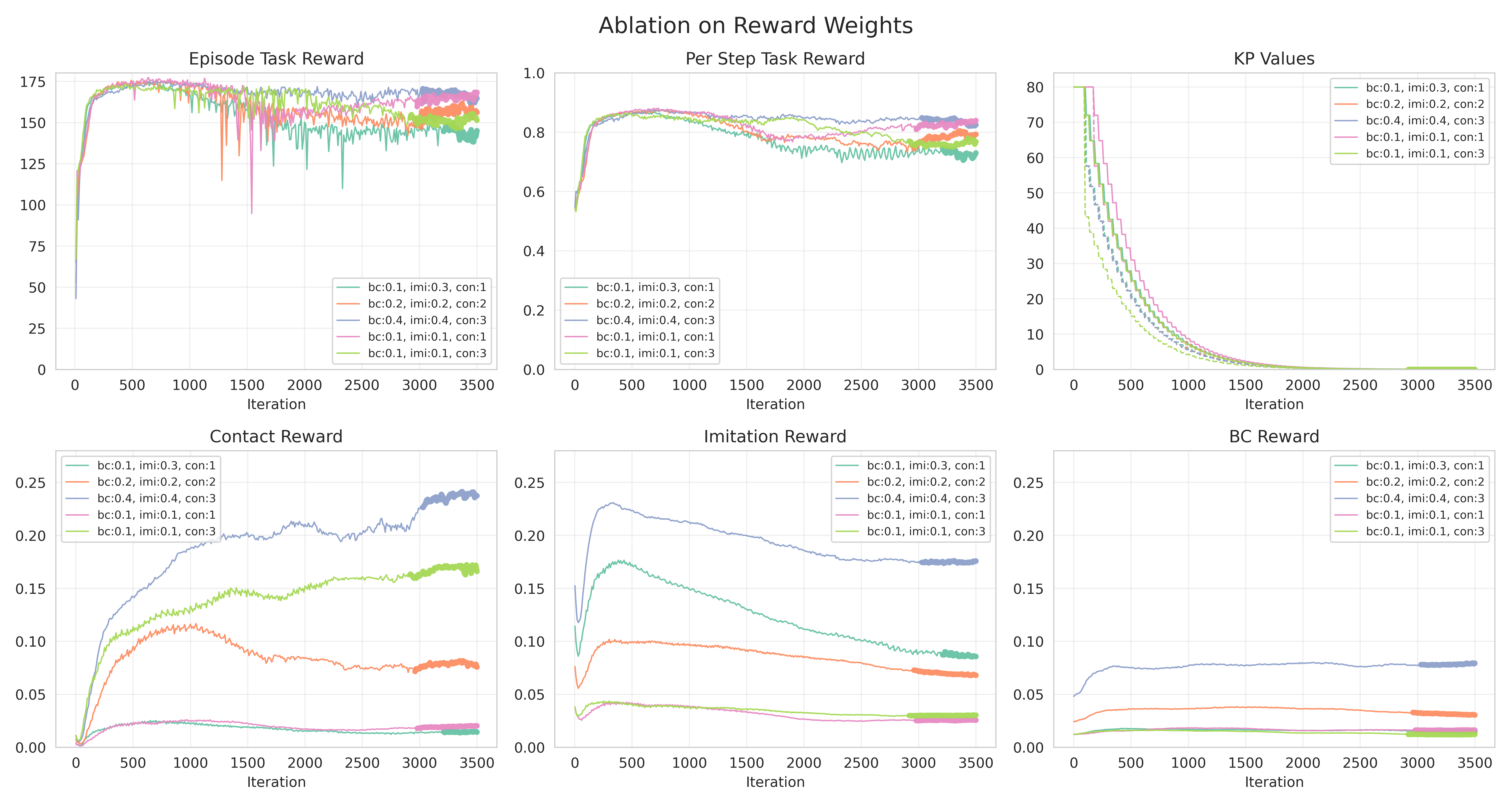
Curriculum Hyperparameters
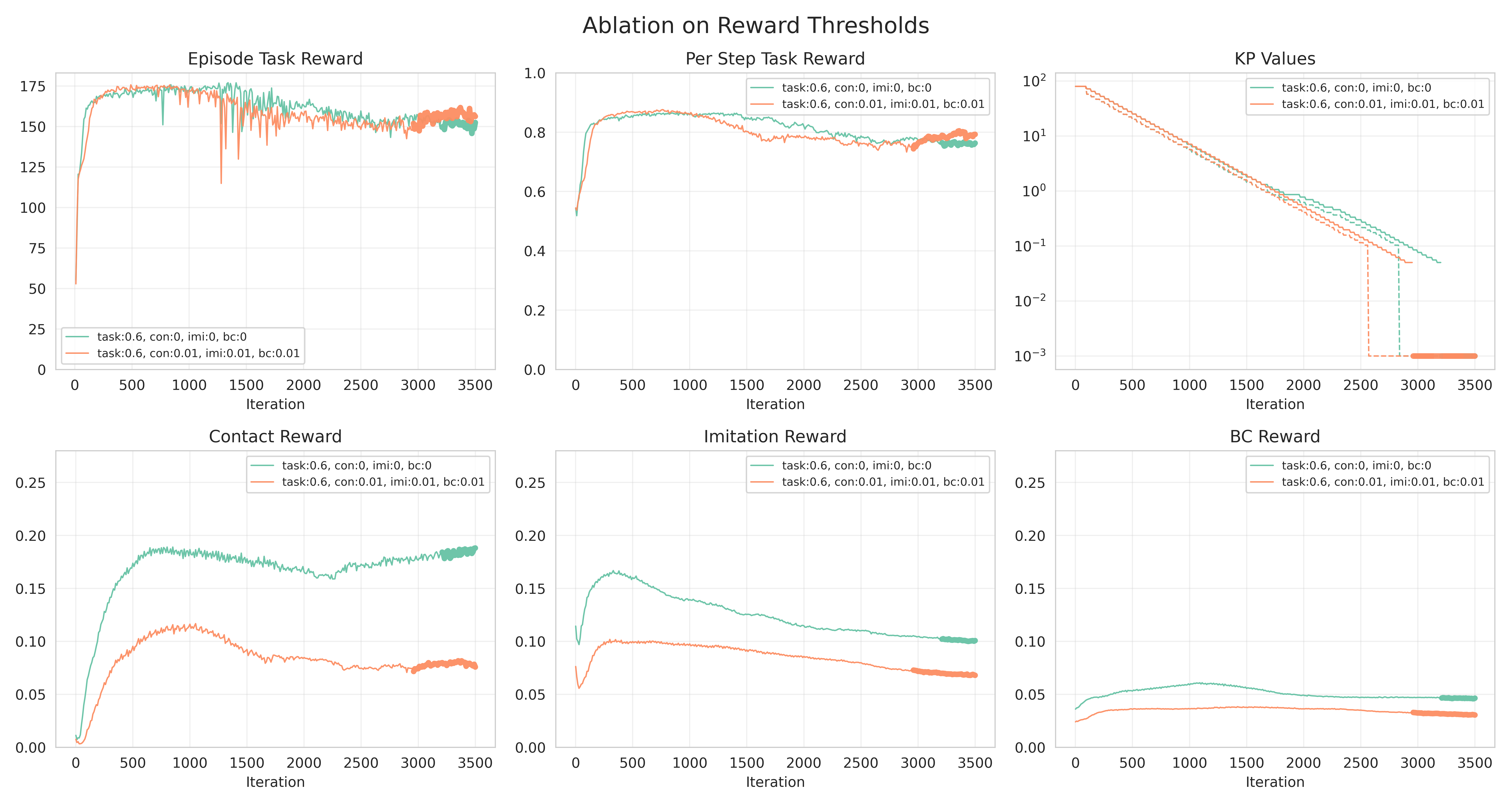
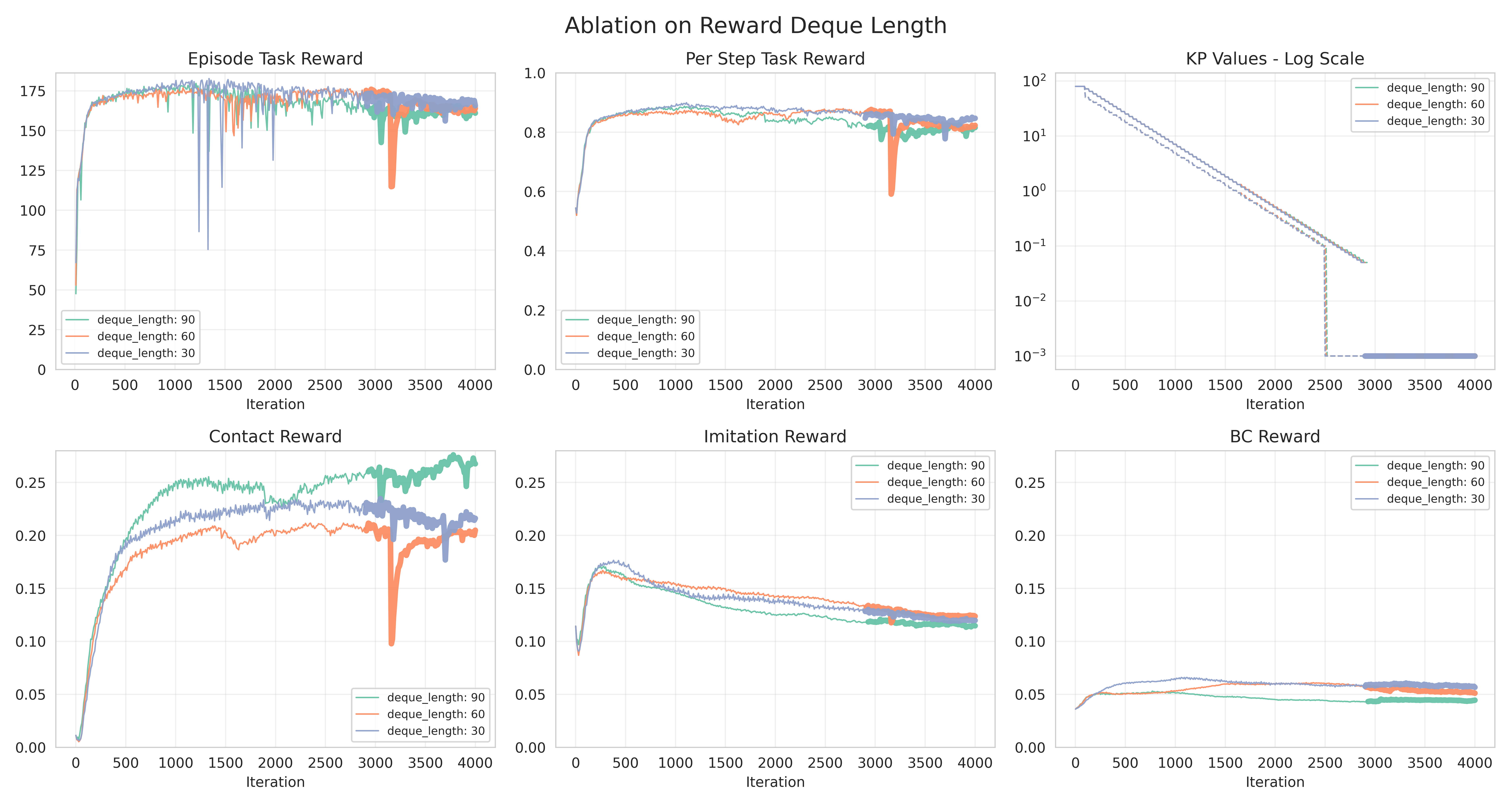
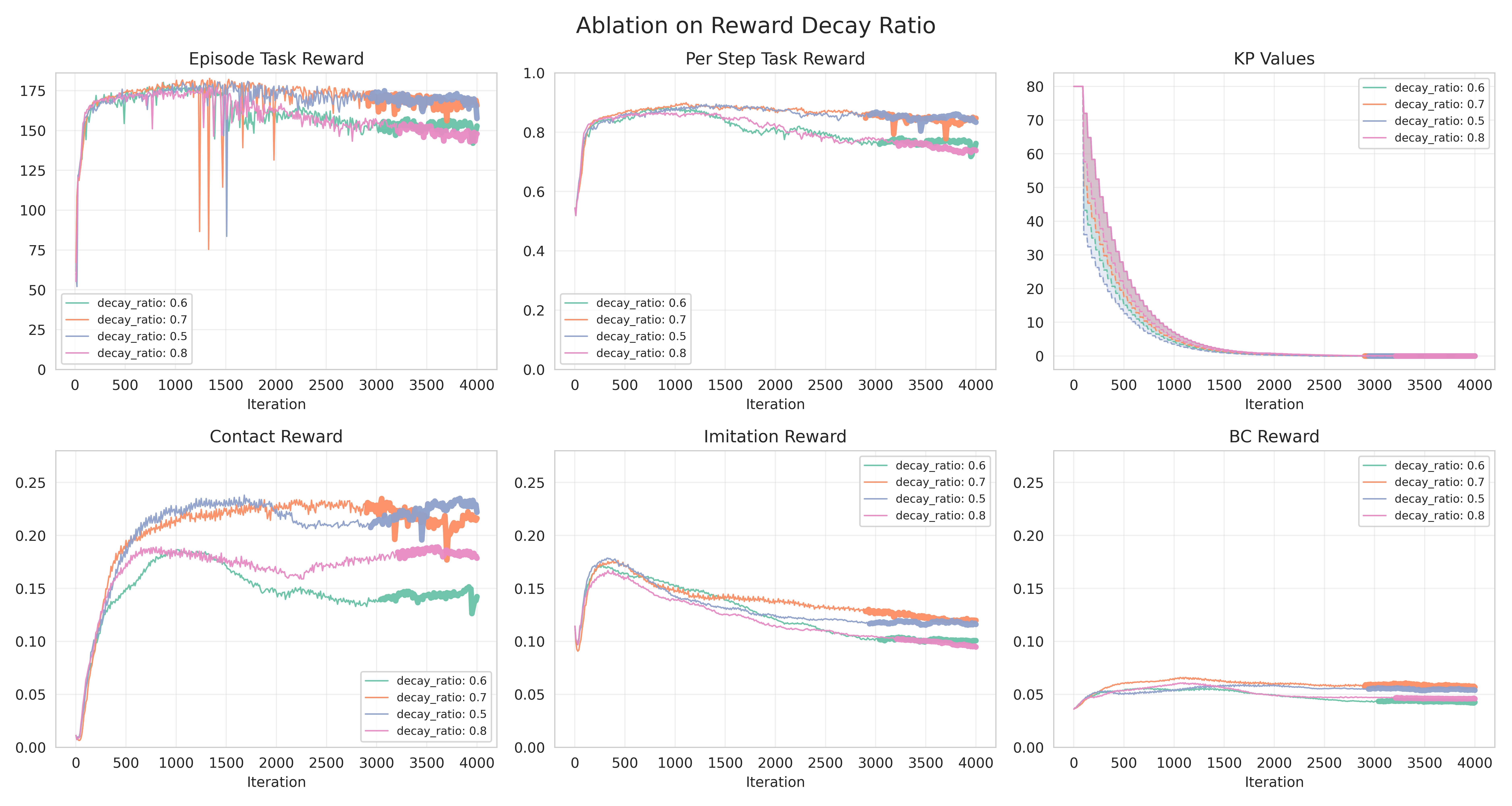
We provide additional experiments to test the sensitivity of our RL training to different hyperparameters in our VOC curriculm. Note that the curves are plotted with a heavier width when the VOC controller gains are reduced to 0, i.e. no virtual forces are applied and the policy must take over the manipulation. Again, 'Episode Task Reward' plots the cumulative task reward achieved in each episode, which directly reflects the policy's object tracking performance.
- Decay reward thresholds.
- Curriculum rewards dequeue lengths.
- VOC controller gain decay ratio.
We keep a separate deque and threshold for each reward term (i.e. task reward, contact reward, imitation reward), and only decay the curriculum's VOC controller gains when the achieved rewards are above the given threshold. In the below experiments, we keep the task reward threshold the same (0.6) and compare using 0.01 vs 0 for the auxiliary rewards thresholds. We observe that, while the two cases achieve similar task reward after VOC controller gains are decayed to zero and both have a downward trend on the auxiliary rewards, having a non-zero threshold helps the policy achieve higher auxiliary rewards, and we qualitatively see a style difference in the learned policy behaviors. This suggests our framework offers flexibility that allows a user to adjust the policy behaviors by tuning these thresholds while not interfering with the task performance.
We compare different deque lengths (30, 60, 90) under the same task and robot hand setting. Intuitively, a longer deque means the moving reward average gets updated more slowly. Hence we observe overall similar task reward outcomes, but slightly slower decay when the deque length is longer, i.e. the policy requires more iterations before transitioning to the next curriculum stage with lower VOC controller gains.
In our VOC curriculum, the controller gain values (i.e. kp and kv) are drawn from a uniform distribution with decaying upper and lower bounds. For kp, we sample (N,) different values (N is number of parallel RL environments) from where the bounds are exponentially decayed at every iteration where the rewards are above their respective thresholds. The sampling distribution is Uniform~[kp_lower, kp_upper], where at each decay, kp_lower = kp_lower_prev * kp_decay_factor_lower, kp_upper = kp_upper_prev * kp_decay_factor_upper. Therefore, different decay_factors determine different schedule of decaying ranges for the gain distributions. In the additional experiments below, we fix kp_decay_factor_upper=0.9 and vary kp_decay_factor_lower from 0.5 to 0.8 (hence the plotted kp ranges are 'wider' vs 'narrower'), and show that the task performance (i.e. object tracking accuracy) is relatively insensitive to different bounds. The reward fluctuations will likely be smoothed out when averaged across multiple random seeds.
Extra Long Horizon
We show our method can successfully handle longer-horizon tasks than our main experiments. The main experiments in the paper used human demonstrations of up to 300 time-steps, here we extend it to up to 600 steps on the same box and mixer demonstrations. Below we show qualitative video of the learned policies where the Allegro hand successfully completes the following human demonstration clips (we mark them as object-start-end): left: Mixer-0-500, middle: Box-30-530, right: Box-0-600.